
Machine Learning ist ein Begriff, den viele Menschen schon einmal gehört oder gelesen haben.
Aber wissen sie dadurch, was das eigentlich ist? Wahrscheinlich nicht, oder?
Wollen Sie Machine Learning begreifen und erfahren, was das ist und was es uns wirklich bringt? Das ist verständlich. Deshalb hier eine kurze und knappe Definition, die das Wichtigste auf den Punkt bringt:
Machine Learning oder maschinelles Lernen nutzt Daten, um Vorhersagen zu treffen.
Das gilt vor allem für Daten, die in sehr großen Mengen vorhanden sind und bei denen der Mensch schnell den Überblick verlieren würde. Hier ist ein Beispiel, damit Sie wissen, was damit gemeint ist:
Machine Learning nutzen, um Kreditkartenbetrug zu verhindern
Stellen Sie sich vor, Sie sind Inhaber einer Kreditkarte und kaufen normalerweise nur Dinge in Ihrem Heimatland. Eines Tages bemerken Sie auf Ihrer Abrechnung eine verdächtige Transaktion für teure Elektronik, die in einem anderen Land getätigt wurde. Und das, obwohl Sie gar nicht dorthin gereist sind.
Mit anderen Worten: Es ist etwas vorgefallen, das sehr nach Betrug riecht.
Und hier kommt Machine Learning ins Spiel.
Die Kreditkartenunternehmen verwenden Machine Learning-Algorithmen, um alle Transaktionen genau zu überwachen.
Sie schauen sich dazu große Mengen an Daten an, einschließlich längst vergangener Transaktionen.
Was dabei eine Rolle spielt: Daten. Ein paar Beispiele für solche Daten:
- die vorliegenden Standortinformationen
- Ihre Kaufgewohnheiten
- sonst übliche Ausgaben pro Woche oder im Monat
In Ihrem Fall würde das System erkennen, dass der ungewöhnliche Kauf in einem fremden Land nicht zu Ihrem normalen Verhalten passt.
Durch Machine Learning „merkt“ das System also, das etwas anders ist als sonst. Womit? Mit den vorliegenden Daten.
Je mehr Daten das System hat – also je mehr es über das normale Kaufverhalten der Kreditkarteninhaber lernt – desto besser kann es zwischen normalen Transaktionen und möglichen Betrugsfällen unterscheiden.
In diesem Beispiel ermöglicht Machine Learning den Kreditkartenunternehmen, verdächtige Aktivitäten zu erkennen. Es kann Sie als Kunde vor möglichen Betrugsfällen schützen.
Etwa, indem es Transaktionen überwacht und bei ungewöhnlichen Vorgängen Vorsichtsmaßnahmen ergreift. So lässt sich etwa die Karte sperren. Auch möglich: die Kontaktaufnahme mit Ihnen, um zu überprüfen, ob die Transaktion auch von Ihnen durchgeführt wurde. Das kann zum Beispiel eine E-Mail sein, die Sie erst bestätigen müssen.
Vielleicht kennen Sie das von Ihren Google-Konto, wenn Sie sich auf einem neuen Gerät anmelden. Dann „fragt“ Goole per Mail nach, ob Sie das waren.
Doch nun wieder zurück zum eigentlichen Thema dieses Beitrags. Werfen wir einen Blick auf Machine Learning.
Machine Learning im Überblick
Es geht also darum, wie Systeme für die Datenverarbeitung aus Daten lernen. Maschinelles Lernen (kurz ML) ist ein faszinierender Bereich der künstlichen Intelligenz (KI).
Es werden Algorithmen und Modelle geschaffen, die es Computern ermöglichen, eigenständig aus Daten zu lernen. Sie erkennen Muster in diesen Daten.
Im Wesentlichen geht es also darum, Maschinen so zu programmieren, dass sie nicht nur stumpf bestimmte Aufgaben ausführen. Vielmehr sollen sie auch die Fähigkeit entwickeln, aus Erfahrungen zu lernen und sich selbst verbessern.
Genau das ist maschinelles Lernen. Es geht um das ständige Weiterentwickeln und Lernen, das auch Maschinen und Computersysteme beherrschen.
Dabei spielt die Verarbeitung sehr großer Datenmengen eine wichtige Rolle. Diese dienen dem Algorithmus als Grundlage für das Training, also das eigentliche Lernen.
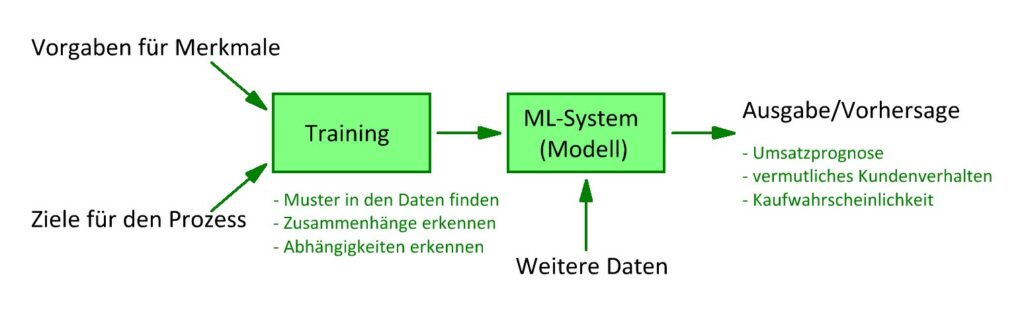
Supervised Learning, Unsupervised Learning, Reinforcement Learning
Machine Learning wird in verschiedenen Methoden unterteilt, darunter Supervised Learning, Unsupervised Learning und Reinforcement Learning.
Jede Methode hat ihre eigenen Anwendungsbereiche:
Von der Vorhersage von Trends bis zur autonomen Entscheidungsfindung von Robotern.
Durch die kontinuierlichen Fortschritte, insbesondere im Bereich Deep Learning, eröffnet Machine Learning ganz neue Möglichkeiten in zahlreichen Branchen. Diese reichen von der Medizin bis zur Finanzwelt. Maschinelles Lernen trägt so mit dazu bei, unseren Alltag nachhaltig zu verändern.
Auf die verschiedenen Arten und ihre Bezeichnungen gehen wir gleich etwas näher ein. Doch zunächst geht es hierum:
Die Definition von Machine Learning
Maschinelles Lernen oder auch Machine Learning bedeutet also, dass Systeme die Fähigkeit erhalten, aus Erfahrungen, sprich Daten, zu lernen. Sie lernen außerdem, sich selbstständig zu verbessern. Und das ohne Programmierung oder Nutzereingriffe.
Worum geht es dabei?
Ganz einfach: Es geht darum, automatisch Wissen zu generieren, Algorithmen zu trainieren und Muster sowie Zusammenhänge in Daten zu erkennen.
Hier noch einmal die Grundidee, die dahintersteht:
Systeme sollen Muster in Daten erkennen und diese Muster auf unbekannte Datensätze anwenden. Das dient dazu, Vorhersagen zu treffen und Prozesse zu optimieren.
Im Gegensatz zur herkömmlichen Softwareentwicklung liegt der Fokus beim maschinellen Lernen auf dem eigenständigen Lernen aus den vorliegenden Daten. Dies bedeutet, dass der Algorithmus aus den Daten lernt. Er ist außerdem in der Lage, seinen Programmcode eigenständig zu erstellen oder zu ändern.
Maschinelles Lernen kann vielfältige Aufgaben bewältigen. Hier sind ein paar Beispiele dafür:
- Es kann vorhersagen, wie viel Strom Sie in der Zukunft wahrscheinlich verbrauchen werden. Das geschieht basierend auf Daten, die über Ihren bisherigen Stromverbrauch gesammelt wurden.
- Machine Learning kann Wahrscheinlichkeiten berechnen. Etwa, wie wahrscheinlich es ist, dass jemand ein Produkt kaufen wird oder dass jemand seinen Vertrag kündigt.
- Außerdem kann es in großen Datenmengen Gruppen oder Cluster identifizieren. Das ist vergleichbar damit, wenn Sie Fotos sortieren und Gruppen von Freunden zusammenstellen.
- Es kann auch Muster in aufeinanderfolgenden Ereignissen erkennen. Beispiel: in einer Reihe von Aktionen auf einer Website durch die Webseitenbesucher.
- Maschinelles Lernen hilft, die Anzahl der verschiedenen Informationen zu reduzieren, ohne dass dabei wichtige Daten verloren gehen.
- Und schließlich kann Machine Learning helfen, Geschäftsabläufe zu verbessern, indem es Prozesse effizienter macht.
Damit maschinelles Lernen effektiv ist und die Software fundierte Entscheidungen treffen kann, ist eines wichtig:
Training für den Algorithmus.
Dies geschieht durch Trainings- und Beispieldaten, durch die der Algorithmus Muster und Zusammenhänge erkennt. Das ist ein Prozess, der als Modelltraining bezeichnet wird.
Häufig werden die Begriffe Data Mining und predictive Analytics im Zusammenhang mit maschinellem Lernen verwendet. Letztendlich greifen Data Mining und predictive Analytics auf die Verfahren des maschinellen Lernens zurück, um Erkenntnisse aus Daten zu gewinnen und um Vorhersagen zu treffen.
Wie funktioniert Machine Learning? Ein Einblick in den Lernprozess der Maschine
Machine Learning ist dem menschlichen Lernen ähnlich, oder nicht?
Im Prinzip schon, auch wenn es ein paar Unterschiede gibt.
Ähnlich wie ein Mensch durch wiederholtes Üben und Differenzieren lernt, kann auch ein Computer durch Befehle des Programmierers und entsprechende Dateneingabe verschiedene Objekte erkennen und unterscheiden.
Wichtig dabei ist aber die Qualität der zugeführten Daten, die eine entscheidende Rolle spielen.
Der Programmierer agiert als Lehrer für die Maschine, der kontinuierliches Feedback gibt. Das entwickelte Algorithmusmodell nutzt dieses Feedback, um sich anzupassen und zu optimieren.
Jeder zusätzliche Datensatz, der dem System zugeführt wird, trägt zur Feinjustierung und Verbesserung des Modells bei. Zusätzliche Daten sorgen also für mehr Präzision. Menschen verwirren zu viele Daten oft nur. Vielleicht ist das einer der wichtigsten Unterschiede zum menschlichen Lernen.
Das übergeordnete Ziel des Machine Learning ist die klare Differenzierung zwischen Objekten und Menschen.
Jedoch geht Machine Learning darüber hinaus. Es geht um die Fähigkeit, sich schnell an sich verändernde Bedingungen anzupassen. Dies ermöglicht eine effiziente Reaktion auf neue Herausforderungen und eine flexible Anpassung der Handlungsweise im praktischen Einsatz.
Was bedeutet das?
Durch maschinelles Lernen sind Computersysteme und Maschinen überhaupt erst in der Lage, sich an neue Situationen und Umstände anzupassen. Und das war nicht immer so.

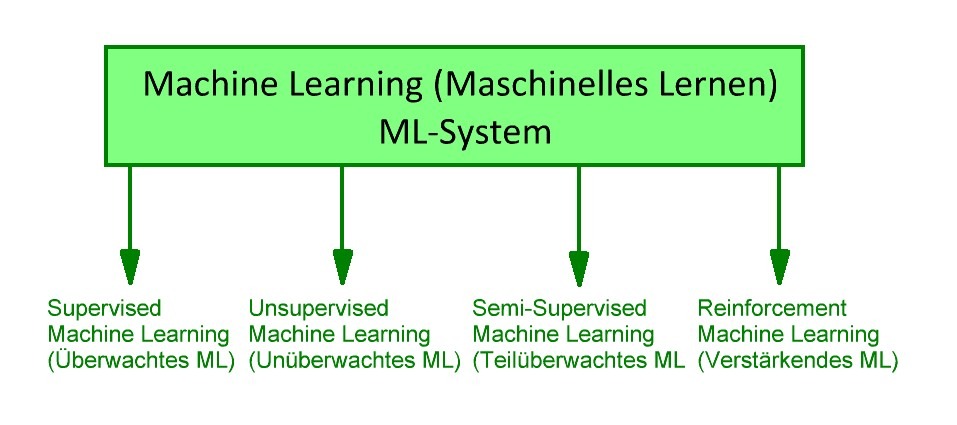
Die verschiedenen Arten des maschinellen Lernens
Jetzt geht es erstmal um die verschiedenen Arten des maschinellen Lernens, die Sie bereits aus einem Abschnitt weiter oben kennen:
- Supervised Learning oder überwachtes Lernen
- Unsupervised Learning oder unüberwachtes Lernen
- Semi-Supervised Learning oder teilüberwachtes Lernen
- Reinforcement Learning verstärkendes Lernen
Überwachtes Lernen: Daten nutzen mithilfe von Mustern
Beim überwachten Lernen (Supervised Learning) nutzt man bekannte Daten, um Muster und Zusammenhänge zu identifizieren. Es ist auch als Supervised Machine Learning bekannt.
Hierbei lernt der Algorithmus aus einem Trainingsdatensatz. Dieser enthält Beispieldaten. Wichtig beim überwachten Lernen ist immer die Vorhersage einer Zielvariable. Das System muss also eine Entscheidung aufgrund der vorliegenden Daten treffen. Das kann eine Entscheidung sein oder ein bestimmter numerischer Wert.
Das ist in etwa vergleichbar mit dem Lernprozess bei einem Menschen.
Es gibt verschiedene Aufgaben zu lösen, wobei zunächst die Lösungen mitgeliefert werden. Die Lösungen sind notwendig. Durch sie erkennt das System die Zusammenhänge zwischen den Aufgaben und deren Lösungen. So ist es später in der Lage, selbst Lösungen für die ihm gestellten Aufgaben zu finden.
Durch das Lernen entwickelt der Algorithmus also die Fähigkeit, zuverlässige Vorhersagen für zukünftige oder unbekannte Daten zu treffen.
Dazu ein Beispiel:
In der Marketingwelt nutzt man überwachtes Lernen oft, um das Kundenverhalten anhand von Daten aus der Vergangenheit vorherzusagen. Bestimmte Daten führen zu bestimmten Handlungsweisen.
Das nutzt man, um bestimmte Handlungen (etwa den Kauf eines Produkts) herbeizuführen. Zumindest steigert es die Wahrscheinlichkeit, das Kunden kaufen oder Angebote in Anspruch nehmen.
Hier sind ein paar praktische Anwendungen des überwachten Lernens:
- Vorhersagen des Stromverbrauchs für einen bestimmten Zeitraum.
- Risikobewertung von Investitionen.
- Berechnung von Ausfallwahrscheinlichkeiten in einem Maschinenpark.
- Prognose des Kundenwerts für die kommenden 12 Monate.
Diese Beispiele verdeutlichen die vielseitigen Anwendungsmöglichkeiten des überwachten Lernens. Aus vorhandenen Daten werden präzise Muster erkannt. Und diese Daten nutzt man als Basis für Entscheidungen.
Unüberwachtes Lernen: diesmal ohne vorgegebenen Schlüssel
Jetzt geht es um das Lernen des nächsten Levels, und zwar ohne vorgegebene Ergebnisse.
Das unüberwachte maschinelle Lernen (Unsupervised Machine Learning) bildet das zweite der vier Modelle im Bereich Machine Learning.
Nur gibt es hier eben keine Beispieldaten mehr, mit denen (oder von denen) das System lernen kann. Hier geht es um etwas anderes:
Viele der dem System zugeführten Daten sind unbeschriftet und unstrukturiert. Für Menschen ist das oft der Horror: Ein Daten verarbeitendes System dagegen beginnt eigenständig, Muster und Zusammenhänge zu erkennen. Es nutzt alle relevanten und verfügbaren Daten dafür.
Was ist ein weiterer Unterschied zum überwachten maschinellen Lernen?
Das unüberwachte Lernen orientiert sich stark daran, wie Menschen die Welt wahrnehmen. Was bedeutet das konkret?
Ähnlich wie wir auf Intuition und Erfahrung zurückgreifen, um Dinge zu interpretieren, verbessert eine Maschine ihre Fähigkeit zur Mustererkennung, je mehr Daten sie verarbeitet. In der Welt der Maschinen wird diese „Erfahrung“ durch die Menge an eingegebenen und verfügbaren Daten definiert.
Mehr Daten sind also gleichbedeutend mit mehr Erfahrung.
Beispiele für Anwendungen des unüberwachten Lernens reichen von der Gesichtserkennung und Gensequenzanalyse bis hin zu Marktforschung und Cybersicherheit.
Der Vorteil gegenüber dem überwachten maschinellen Lernen ist folgender:
Diese Methode ermöglicht es, verborgene Zusammenhänge in unstrukturierten Daten zu entdecken und so wichtige Erkenntnisse zu gewinnen, ohne dabei auf vordefinierte Muster angewiesen zu sein.
Das ist enorm wichtig, da beim Machine Learning nicht immer Vergleichsdaten zur Verfügung stehen. Es lassen sich also nicht immer bereits beispielhafte Ergebnisse zum Anlernen des Systems nutzen.
Hier sind noch ein paar Einsatzgebiete dieser Art maschinellen Lernens:
- Große und unbekannte Datenmengen visualisieren
- Durchführen von Analysen von Ähnlichkeiten in sehr großen Datenbeständen
- Regeln aus vorhandenen Datenbeständen extrahieren
Teilüberwachtes Lernen: clevere Kombination von Struktur und Freiheit
In einer idealen Welt wären alle Daten strukturiert und vor der Eingabe in ein System beschriftet.
Aber es gibt keine solche ideale Welt. Und auch die Daten liegen nicht immer so vor, wie man sich das wünscht. Mal sind die Daten sofort einfach nutzbar, manchmal aber auch nicht.
Und hier kommt das teilüberwachte Lernen ins Spiel.
Es ist dann eine praktische Lösung, wenn es um die Verarbeitung riesiger Mengen an Roh- und unstrukturierten Daten geht. Außerdem nutzt man beschriftete Daten.
Beim Semi-Supervised Learning werden kleine Mengen beschrifteter Daten eingegeben, um unbeschriftete Datensätze aufzuwerten. Wozu wird das so gemacht?
Die beschrifteten Daten dienen hier als Ausgangspunkt für das System und können die Lerngeschwindigkeit sowie die Genauigkeit erheblich steigern. Ein teilüberwachter Lernalgorithmus leitet die Maschine dazu an, die beschrifteten Daten zunächst zu analysieren. Es geht dabei darum, Beziehungen zwischen den Daten zu finden, die dann auf die unbeschrifteten Daten angewendet werden können.
Der Grund dafür ist einfach:
Mit dieser Methode ist es möglich, mit einer relativ geringen Menge an beschrifteten Daten das System zu trainieren. Das senkt den Aufwand, an beschriftete Daten zu gelangen, die meist von Menschen generiert beziehungsweise beschriftet werden müssen.
Das ist extrem aufwendig und kostet sehr viel.
Hier ist ein Beispiel dafür:
Bei der Bilderkennung oder beim Erkennen von Objekten wird teilweise überwachtes Lernen verwendet. Dafür erstellt man zuerst einen kleinen Satz mit bekannten Bildern, die von Menschen markiert werden. Danach trainiert man ein künstliches neuronales Netz, um diese Bilder zu erkennen. Dieses trainierte Netz wird dann auf die restlichen unbekannten Daten angewendet.
Auf diese Weise können die unbekannten Bilder schneller und genauer erkannt werden, weil das Netz von den beschrifteten Bildern gelernt hat.
Aber dieses Modell birgt Risiken. Das gilt besonders dann, wenn Fehler in den beschrifteten Daten vom System erlernt und repliziert werden. Unternehmen, die erfolgreich teilüberwachtes Lernen nutzen, stellen deshalb sicher, dass bewährte Praktiken und Vorgehensweisen konsequent umgesetzt werden.
Teilüberwachtes Lernen findet vermehrt Anwendung in Sprach- und linguistischen Analysen, in der komplexen medizinischen Forschung, beispielsweise bei der Kategorisierung von Proteinen sowie in der Betrugserkennung. Diese Methode ermöglicht eine intelligente Kombination von Struktur und Freiheit bei der Verarbeitung von Daten.
Verstärkendes Lernen: Antworten finden ohne vorgegebene Lösungen
Beim verstärkenden (oder bestärkenden) Lernen gibt es keine vorgegebenen Lösungen wie bei den anderen Modellen.
Es ist das vierte Modell im Bereich des maschinellen Lernens. Und es unterscheidet sich grundlegend von den vorherigen Ansätzen. Beim überwachten Lernen erhält die Maschine den Antwortschlüssel, also eine Vorgabe für eine Lösung. Das Modell für bestärkendes Lernen arbeitet ohne einen solchen Schlüssel.
Der Vorteil dabei: Es sind keine Beispieldaten notwendig wie bei den anderen Arten des Lernens. Es gibt lediglich positive oder negative Rückmeldungen, das sogenannte Feedback. Und anhand dieses Feedbacks lernt das System die Einschätzung zur richtigen Handlung bei der jeweiligen Aufgabe.
Das klingt Ihnen alles viel zu abstrakt? Das ist verständlich. Deshalb kommt hier ein Beispiel:
Stellen Sie sich folgendes Szenario vor:
In einer Fabrik gibt es einen Roboterarm, der Teile von einem Förderband aufgreifen und in eine bestimmte Kiste legen soll. Um den Roboter zu trainieren, wird verstärkendes Lernen verwendet.
Zu Beginn hat der Roboter keine vordefinierten Anweisungen, wie er die Teile greifen oder in die Kiste legen soll. Es gibt also keinerlei Vorgaben. Der Roboter muss ausprobieren, wie es geht. Stattdessen wird er mit der Fähigkeit ausgestattet, die Teile zu erfassen und zu bewegen. Der Algorithmus gibt dem Roboter also die Freiheit, verschiedene Bewegungen auszuprobieren. Mehr aber nicht.
Während der Roboter arbeitet, bekommt er positive Verstärkung, wenn er ein Teil erfolgreich aufnimmt und in die Kiste legt. Wenn er jedoch Schwierigkeiten hat oder ein Teil fallen lässt, erfolgt negative Rückmeldung.
So lernt der Roboter immer besser, welche Bewegungen zu positiven Ergebnissen führen und welche er vermeiden sollte.
Man könnte auch sagen: Learning by Doing.
Durch diese adaptive Lernmethode verbessert sich der Roboter kontinuierlich und wird immer geschickter bei der Erfüllung seiner Aufgabe. Genauso wie ein Kind, das Laufen oder Radfahren lernt und durch Ausprobieren immer besser und sicherer wird.
Es gibt also lediglich eine Reihe von zulässigen Aktionen, Regeln und möglichen Endzuständen. Diese sind vorgegeben. Das Ziel steht also fest. In dem Beispiel wäre es das Einsortieren von Dingen in verschiedene Kisten.
Wenn das Algorithmus-Ziel klar oder binär ist, kann die Maschine durch Beispiele lernen. In Fällen, in denen das Ziel variabel ist, muss das System durch Erfahrung und Belohnung lernen. Die „Belohnung“ in den bestärkenden Lernmodellen ist numerisch und im Algorithmus als Anreiz eingebaut, den das System anstrebt.
Das ist ähnlich wie bei einem Punktestand (dem Score) in einem Computerspiel.
Anwendungen für bestärkendes Lernen gibt es in automatisierten Preisangeboten für Online-Werbung, bei der Entwicklung von Computerspielen und im Börsenhandel. In diesen Szenarien ermöglicht bestärkendes Lernen eine intelligente Entscheidungsfindung. Und das ohne vordefinierte Lösungen.
Aktives Lernen: Fragen stellen und Antworten auswerten
Hier könnte man sagen: Wer nicht fragt, bleibt dumm.
Aktives Lernen ist eine sehr intelligente Methode im Bereich Machine Learning. Hierbei fragt das Modell gezielt nach Informationen, um zu lernen. Es wartet also nicht passiv auf vorhandene Daten.
Stattdessen reagiert das Modell eigenständig mit den passenden Fragen an den Benutzer. Das ist dann der Fall, wenn Unklarheiten bestehen. Es bittet also den Benutzer oder ein Expertenteam um zusätzliche Informationen.
Auch dazu ein Beispiel aus der Industrie:
Stellen Sie sich ein Szenario in einem Produktionsunternehmen vor. Man möchte ein maschinelles Lernmodell entwickeln, um Fehler in den Produktionslinien zu erkennen.
Anstatt das Modell nur mit einer vordefinierten Menge von bereits markierten fehlerhaften Produkten zu trainieren, wird hier das aktive Lernen eingesetzt.
Das Modell kann also während des Produktionsprozesses nachfragen, wenn es unsicher ist. Zum Beispiel kann es ein Bild eines Produkts zeigen und fragen:
„Gibt es hier einen Fehler?“
Wenn der Mitarbeiter oder das Überwachungssystem bestätigt, dass ein Fehler vorliegt, nutzt das Modell diese Information, um seinen Fehlererkennungsalgorithmus zu verbessern.
Was ist daran vorteilhaft?
Durch diesen Lernansatz lassen sich begrenzte Ressourcen an Daten nutzen. Das Modell selbst sucht gezielt nach den wichtigsten Informationen, um seine Genauigkeit zu steigern.
Es ist so, als würde man einen Menschen mit einer neuen Aufgabe betrauen. Ist er sich unsicher, was er tun soll, fragt er einfach bei einem erfahrenen Mitarbeiter nach.
Aktives Lernen ist also ebenfalls eine dem menschlichen Lernen nachempfundene Methode.
9 Einsatzgebiete für das maschinelle Lernen oder Machine Learning
Machine Learning ist sehr nützlich und hilft, Prozesse zu automatisieren.
Das haben natürlich auch die großen Unternehmen erkannt. Deshalb nutzen diese das maschinelle Lernen immer häufiger. Und deshalb geht es hier auch um die möglichen Einsatzgebiete von Machine Learning. Hier sind 9 Beispiele:
- In der Qualitätskontrolle und in der Fertigung lässt sich Machine Learning einsetzen, um Muster von fehlerhaften Produkten in Echtzeit zu erkennen. Kameras überwachen die Produktionslinie. Das System identifiziert dabei Unregelmäßigkeiten. Und das alles, um die Qualität in der Fertigung zu verbessern.
- In der vorausschauenden Wartung (Predictive Maintenance) nutzt man ebenfalls maschinelles Lernen. Hier prognostizieren entsprechend trainierte Systeme anhand von Sensordaten den optimalen Zeitpunkt für die Wartung von Maschinen. Dies hilft, ungeplante Ausfallzeiten zu minimieren. Es geht also um die Effizienz der Produktion und darum, diese zu steigern.
- Die Lieferkettenoptimierung ist ebenfalls ein wichtiges Anwendungsgebiet für Machine Learning. Durch die Analyse großer Datenmengen hilft Machine Learning dabei, Lieferketten effizienter zu machen. Wie funktioniert das? Das System kann Lieferzeiten vorhersagen, Lagerbestände optimieren und Engpässe frühzeitig feststellen.
- Das Energiemanagement ist ein weiteres Beispiel. Eine mögliche Anwendung: Machine Learning optimiert den Energieverbrauch in Fabriken. Das System analysiert den Energiebedarf basierend auf dem aktuellen Produktionsvolumen und anderen Faktoren. So lässt sich der Energieverbrauch minimieren. Das hat natürlich positive Auswirkungen auf die Nachhaltigkeit von Produkten.
- Auch bei der Produktionsplanung und -optimierung hilft Machine Learning. Mit trainierten Systemen lassen sich Produktionspläne erstellen. Dazu nutzt man historische Daten, Prognosen und berücksichtigt vorhandene Ressourcen. Die Produktionsanlagen sind besser ausgelastet. Auch das steigert die Effizienz in den Unternehmen.
- Robotergesteuerte Prozesse gibt es schon sehr lange. Roboter in der Fertigung können komplexe Aufgaben mithilfe von Machine Learning oft viel effizienter bewältigen. Dies reicht von der Montage von Produkten bis hin zu deren Verpackung.
- Und was die Nachhaltigkeit angeht: Mit Machine Learning lässt sich der ökologische Fußabdruck der Industrie reduzieren. Es optimiert den Verbrauch von Ressourcen. Abfall lässt sich minimieren und umweltfreundliche Produktionspraktiken fördern.
- Machine Learning lässt sich auch im Kundenservice einsetzen. Mithilfe von Chatbots oder personalisierten Empfehlungen lässt sich der Kundensupport verbessern. Auch auf individuelle Anforderungen der Kunden kann besser eingegangen werden.
- Nicht zu vergessen: das Marketing: Vorlieben der Kunden und deren Verhalten sind sehr wertvolle Daten, die sich mithilfe von maschinellem Lernen nutzen lassen. Kennen Sie die Produktempfehlungen auf den gängigen Webseiten von Onlineshops? Denken Sie an Sätze wie: „Kunden, die dieses Produkt kaufen, kauften auch …“.
Und ebenfalls wichtig:
Sogar personalisierte Webseiten lassen sich umsetzen. Kennzahlen lassen sich nutzen, um personalisierte Marketingstrategien zu entwickeln.
Denken Sie an Werte wie Customer Lifetime Value CLV (Kundenertragswert, vergleichbar mit dem Gesamtumsatz eines Kunden, solange dieser Kunde ist), Recency (Aktualität), Frequency (Häufigkeit) und Monetary Value (Geldwert oder Umsatz), kurz RFM.
9 gängige Algorithmen beim Machine Learning
Es gibt inzwischen eine Vielzahl von Algorithmen im maschinellen Lernen. Hier ist eine kleine Übersicht, was es unter anderem gibt:
- Die Lineare Regression (Linear Regression) wird für die Vorhersage von kontinuierlichen Werten verwendet. Der Algorithmus modelliert die Beziehung zwischen einer abhängigen Variable und mindestens einer unabhängigen Variable.
- Logistische Regression (Logistic Regression): Im Gegensatz zur linearen Regression wird die logistische Regression für die Klassifikation verwendet. Sie prognostiziert die Wahrscheinlichkeit, dass eine Beobachtung einer bestimmten Klasse angehört.
- Entscheidungsbäume (Decision Trees) repräsentieren Entscheidungsregeln in einem baumartigen Diagramm. Sie werden für Klassifikation und Regression verwendet, indem sie den Datensatz in Untergruppen aufteilen.
- Random Forest ist eine Ensemble-Methode, die aus mehreren Entscheidungsbäumen besteht. Sie verbessert die Vorhersagegenauigkeit und reduziert Überanpassungen.
- k-Nearest Neighbors (k-NN) ist ein einfacher Klassifikationsalgorithmus, der basierend auf der Mehrheit der k-nächsten Nachbarn einer Beobachtung eine Vorhersage trifft.
- Support Vector Machines (SVM) ist ein leistungsstarker Algorithmus für Klassifikation und Regression. Er sucht nach der optimalen Trennung zwischen den Klassen im Feature-Raum.
- K-Means ist ein Clustering-Algorithmus, der Daten in k Gruppen oder Cluster aufteilt. Er eignet sich gut für die Identifizierung von Mustern in undefinierten Daten.
- Neuronale Netzwerke (Neural Networks) sind komplexe Modelle, die von biologischen neuronalen Netzwerken inspiriert sind. Sie eignen sich für komplexe Aufgaben wie Bilderkennung und natürliche Sprachverarbeitung.
- Gradient Boosting ist eine Ensemble-Technik, bei der schwache Modelle schrittweise verbessert werden, indem sie sich auf die Fehler vorheriger Modelle konzentrieren. XGBoost und LightGBM sind beliebte Implementierungen davon.
Wie läuft der Lernprozess beim maschinellen Lernen ab?
Nun geht es darum, wie der Lernprozess beim Machine Learning abläuft.
Dieser Lernprozess erfolgt in mehreren Schritten. Dabei gibt es mehrere Durchläufe dieses Machine-Learning-Prozesses. Hier sind aber erst einmal die einzelnen Schritte:
Erst geht es um die Problemdefinition, die Zielsetzung und Austausch von Wissen. Was heißt das?
Vor dem Start müssen die Ziele und der Anwendungsbereich des Machine Learning klar definiert werden. Welche Schritte oder Prozesse sollen durch maschinelles Lernen optimiert werden? Wie sieht die Zielvorgabe aus? Gibt es bestimmte Zahlenwerte, die erreicht werden sollen oder müssen?
Danach geht es um Daten und deren Beschaffung. Außerdem wichtig: die richtige Auswertung dieser Daten und das Erkennen von Mustern in diesen Daten. Ein wichtiger und notwendiger Schritt, außerdem ein nicht ganz unproblematischer. Der Grund:
Die Verarbeitung von Daten ist entscheidend und oft zeitintensiv. Die Nutzung hochwertiger Daten ist wichtig. Ein zentraler Datenspeicher, in dem alle für den Betrieb wichtigen Daten abgelegt sind, ist hierbei sehr nützlich. Oft ist dieser der wichtigste Bestandteil und die Grundlage für Machine-Learning-Projekte.
Danach kommt die eigentliche Lernphase. Hier findet also das eigentliche maschinelle Lernen statt. Bei diesem trainiert man den Machine Learning-Algorithmus. Mit dem menschlichen Lernen verglichen, könnte man sagen, Erfahrungen werden gesammelt.
Dann kommt schließlich die Interpretation der Ergebnisse: Das ist essenziell. Außerdem wichtig: ein gewisses Verständnis für den Algorithmus. Das ist enorm wichtig für die Akzeptanz von maschinellem Lernen im Fachbereich. Die Menschen möchten schließlich verstehen, was im Algorithmus geschieht und wie der Lernprozess funktioniert.
Was wäre maschinelles Lernen ohne die produktive Nutzung?
Antwort: Nichts.
Das Entwickeln von Machine Learning allein bringt nichts. Ohne Integration in reale Prozesse bringt es keinen Mehrwert. Die technischen Anforderungen für Machine Learning sind komplex. Außerdem ist es oft gar nicht so einfach, die daraus gewonnenen Erkenntnisse so umzusetzen, dass eine produktive Nutzung möglich ist.
Aber wenn dies doch geschieht, gibt es oft einen enorm großen Nutzen.
Aber der eben geschilderte Lernprozess ist kein einmaliger Vorgang. Dieser Zyklus wird wiederholt, bis die gewünschten Ergebnisse erzielt werden. Und zwar solange, bis die Ergebnisse den Wünschen beziehungsweise Vorgaben entsprechen.
Machine Learning ist also ein Kreislauf.
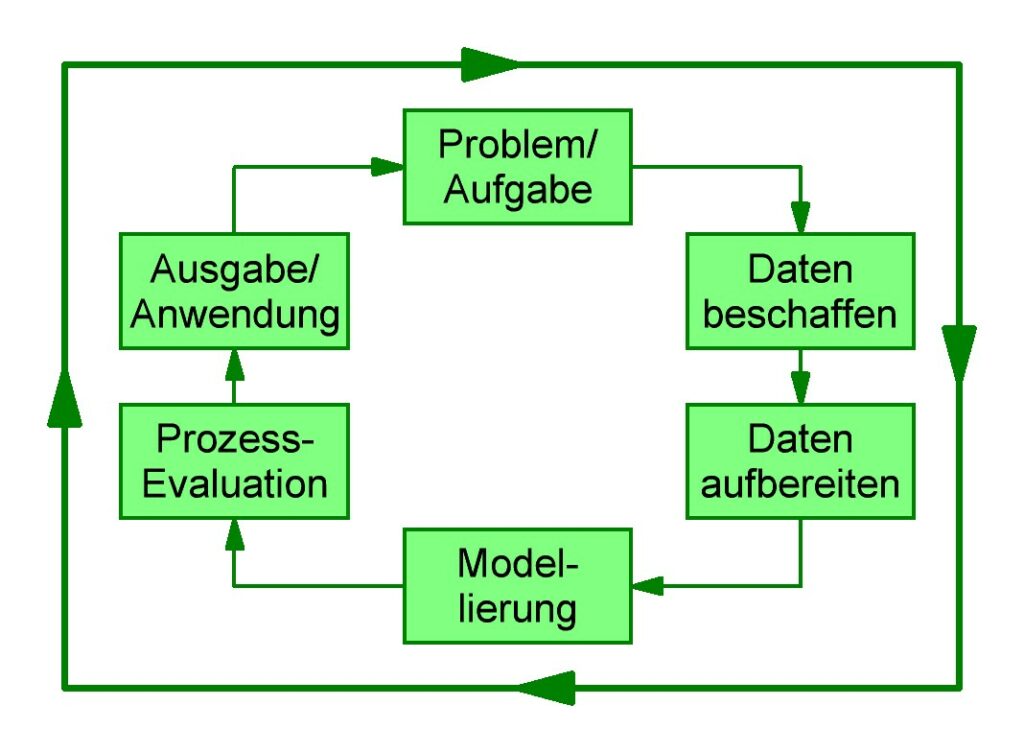
Ein oft beschriebenes Modell in der Literatur ist der CRISP-DM Prozess, der ursprünglich für Data Mining entwickelt wurde. CRISP DM steht für CRoss Industry Standard Process for Data Mining. Obwohl nicht ausschließlich auf Machine Learning ausgerichtet, integriert dieser Prozess auch die Ziele aus Sicht der Business-Anwendung.
Der CRISP-DM (CRoss Industry Standard Process for Data Mining) ist ein strukturierter Prozess, der für Datenanalyse und Data-Mining-Projekte entwickelt wurde. Dieser Standardprozess besteht aus sechs Hauptphasen: Verständnis des Geschäftsproblems, Verständnis der Daten, Datenvorbereitung, Modellbildung, Evaluierung und Bereitstellung.
Aber bevor es jetzt hier zu verwirrend wird: Der CRISP-DM-Prozess ist aber ein eigenes Thema, zu dem noch ein weiterer Beitrag folgt.
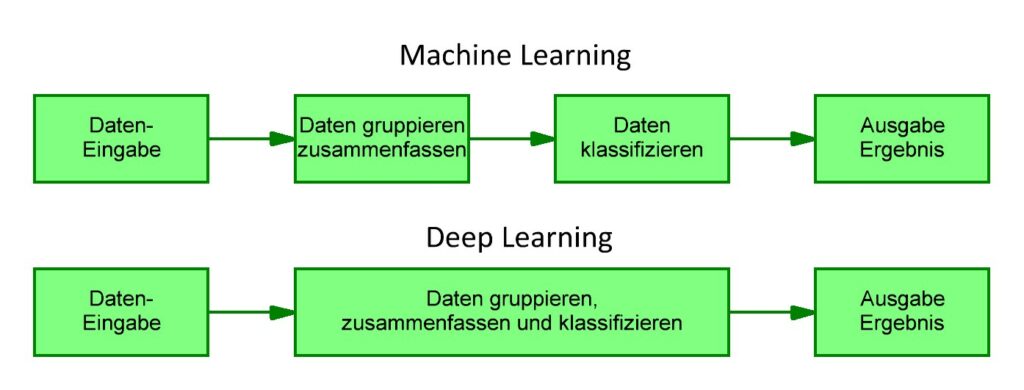
Unterschiede Machine Learning und Deep Learning
Machine Learning und Deep Learning sind zwar verwandte Begriffe. Trotzdem gibt es einige wichtige Unterschiede, auf die hier eingegangen werden soll.
Zunächst zu Machine Learning (ML):
Machine Learning ist ein Lernprozess, die sich auf Techniken und Modelle bezieht, bei denen ein Computer (oder System) aus Erfahrung lernt. Es umfasst verschiedene Arten von Algorithmen, darunter Entscheidungsbäume, k-Nearest Neighbors, und viele andere.
Die Daten für die Vorhersagen müssen normalerweise manuell ausgewählt oder erstellt werden.
ML-Modelle funktionieren meist sehr gut, wenn genügend Daten vorhanden sind, aber sie haben manchmal Schwierigkeiten, komplexe Muster in sehr großen Datenmengen zu erfassen.
Nun zu Deep Learning (DL):
Deep Learning ist eine spezielle Form des Machine Learning, die auf künstlichen neuronalen Netzwerken basiert. Es ist also eine Unterkategorie von Machine Learning.
Es verwendet mehrschichtige neuronale Netzwerke, um automatisch relevante Merkmale aus den Daten zu lernen. Im Gegensatz zum herkömmlichen Machine Learning müssen beim Deep Learning keine manuellen Funktionen ausgewählt werden. Deep Learning ist besonders gut für die Verarbeitung großer Datenmengen und das Erkennen komplexer Muster geeignet.
Die Deep-Learning-Modelle sind leistungsfähiger, benötigen jedoch oft mehr Daten und Rechenressourcen als ML-Modelle.
Mit einfachen Worten:
Deep Learning ist eine fortgeschrittenere Technik im Bereich des Machine Learning, die automatisch tiefere Muster lernen kann, während Machine Learning eine breitere Kategorie ist, die verschiedene Techniken umfasst, auch solche, die nicht auf tiefen neuronalen Netzwerken basieren. Deep Learning ist also maschinelles Lernen, aber nicht immer ist maschinelles Lernen auch Deep Learning.
Auto-ML als Zukunft des Maschinenlernens
Machine Learning (ML) ist eine nützliche Sache. Ein System lernt immer dazu und verbessert sich dadurch.
Es geht aber noch mehr Möglichkeiten im Maschinenlernen. Eine davon ist AutoML. Hier geht es darum, das maschinelle Lernen zu automatisieren.
Automatisiertes Maschinenlernen (AutoML) revolutioniert Machine Learning. Statt die Modellauswahl und deren Architektur mühsam von Data-Science-Teams herausfinden zu lassen, automatisiert AutoML diesen Prozess und minimiert dadurch die Arbeitszeit, in der menschliches Eingreifen in den Lernprozess nötig ist.
Oft reicht es schon aus, dass der Mensch die Ergebnisse des Lernprozesses überprüft. Einige AutoML-Frameworks übernehmen bereits den mühsamen Teil der Datenvorverarbeitung im Maschinenlernen, der laut Forbes etwa 80 Prozent der Zeit eines ML-Projekts ausmacht.
Aber was bleibt für den Menschen in diesem Prozess zu tun?
Die fachliche Expertise und das Design der Datensätze, die zur Lösung des Problems erstellt werden müssen, bleiben weiterhin wichtige Aufgaben für den Menschen.
Fest steht, dass große Unternehmen bereits heute erhebliche Ressourcen in die Automatisierung von ML-Prozessen investieren. Unternehmen wie Amazon Sagemaker und Google haben sogar schon AutoML-Plattformen eingeführt.
Wahrscheinlich werden zukünftig noch viel mehr Prozesse automatisiert. Der Mensch übernimmt dann höchstens noch überwachende oder kontrollierende Aufgaben.
Fazit: Maschinelles Lernen und seine Zukunftspotenziale
Kurz zusammengefasst:
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz und nutzt Algorithmen und statistische Methoden, um Daten zu analysieren und darin Muster zu erkennen. Für Menschen ist es aber schwierig, mit den enormen Datenmengen zurechtzukommen. Für Computersysteme ist das gar kein Problem.
Sie sind in der Lage, wertvolle Informationen allein durch einfache Datenanalysen zu gewinnen. Das ist bereits sehr wertvoll für moderne Unternehmen. Das gilt für produzierende Unternehmen genauso wie für Handelsbetriebe.
Maschinelles Lernen hilft, Informationen auszuwerten, darin Muster zu erkennen und Vorhersagen zu treffen. Das wiederum hilft, die Produktion und Umsätze zu steigern. Die Unternehmen sind in der Lage, jederzeit fundierte Entscheidungen zu treffen und ihre Prozesse erheblich verbessern.
Dabei ist es egal, in welcher Branche die Unternehmen arbeiten.
Auch im Alltag begegnet uns maschinelles Lernen immer wieder. Ob in sozialen Medien, E-Commerce oder in der Medizin. Machine Learning findet fast überall Anwendung. Es wird zunehmend zu einem unverzichtbaren Bestandteil unseres täglichen Lebens, und wir können davon ausgehen, dass es uns in den kommenden Jahren immer stärker begleiten wird.
Daten spielen heute eine größere Rolle den je. Interessieren ie sich dafür. Schauen Sie sich auch den Beitrag über Data Science an.
Content Marketing heißt ähnlich wie Copywriting das ansprechen der eigenen Zielgruppe. Worauf es dabei ankommt und was guter Content damit zu tun hat, können Sie in diesem Beitrag nachlesen.
Digital Marketing umfasst keineswegs nur das, was mit dem Internet zu tun hat. Es geht um ein weit größeres Gebiet. Wenn sich das interessiert, lesen Sie hier weiter.
Neueste Beiträge:
- Autorenwelt: Bücher kaufen und die Autoren unterstützen
- Tonbänder digitalisieren und wie es funktioniert E-Book
- CB-Funk – der neue Einstieg
- Röhrentechnik für Einsteiger
- Warum heute Elektronik-Bücher kaufen und lesen?
Die Blogkategorien: